

Case #010 - Matching Errors can also be a Hijacking Issue
The system accepted the brand owner's data but ranked the hijacker's foreign-language contribution higher.
If you’re new here, welcome.
If you’ve been reading for a while, thank you for being here.
Each week, we break down one real Amazon case from the field. Not to share tactics, but to decode how Amazon’s system actually behaves and what to do when it breaks.
All past cases live in a single searchable archive, built to help you identify recurring patterns across time.

Context
Why the logic failed
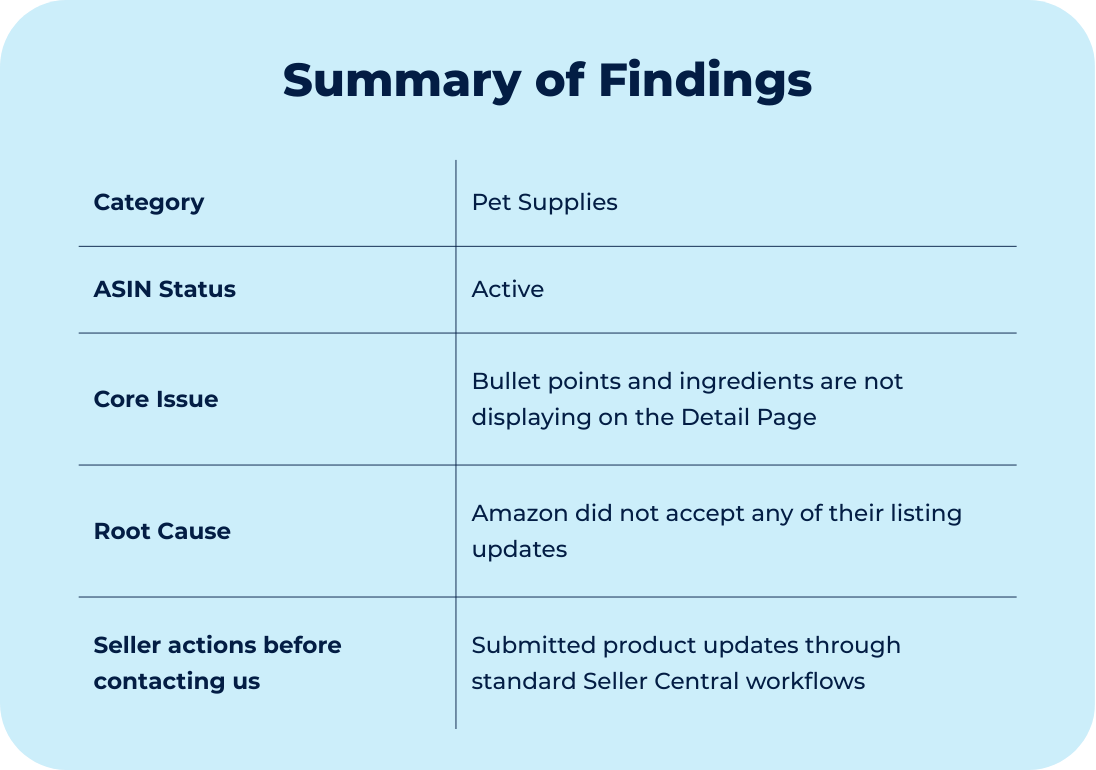
We have covered matching errors in previous cases. The pattern is familiar: you submit data, the system accepts it, but nothing appears on the detail page. In thousands of cases, this happens because your contribution is lost to a higher-ranked one from a legitimate source.
But this case is different. This is a matching error caused by hijacking.
The brand owner submitted accurate English-language content for their own ASINs in the US marketplace. The competing contribution was in Taiwanese and Chinese. It had nothing to do with the product and came from an internal Amazon contributor. The system appeared to accept the brand owner’s data, but the hijacker’s foreign-language contribution remained winning.
A standard matching error occurs when the system ranks another legitimate contribution higher, typically from a data augmenter or retail source. But the internal hijacker added foreign-language content knowing the system would accept and rank it but not display it because the language doesn’t match the marketplace. While invisible to customers, the contribution remains active in the backend, where it can block the rightful owner from overwriting it.
The real issue was deeper: the brand owner’s contribution never made it into the ranking competition. The ingredients attribute exceeded the 500-character limit for this category. The Seller Central UI accepted the submission without displaying an error, but the system silently rejected it at validation. The hijacker’s contribution won by default, not because it ranked higher, but because it was the only valid contribution.
Amazon’s catalog stores multiple contributions from different sources and selects one to display based on contribution ranking. The seller’s data never passed validation, so it couldn’t compete. The UI didn’t communicate this failure.
Diagnostic
What the system did
An internal Amazon contributor submitted bullet points in Taiwanese and ingredient lists in Chinese on the US marketplace. That contributor had a lower contribution rating than a brand-registered seller. However, no higher-ranked contribution existed at the time, so the foreign-language data became the winning contribution.
When the brand owner submitted English-language data via Seller Central, the system accepted it but did not promote it to winning status. The contribution ranking algorithm did not elevate the seller’s submission above the Amazon contributor’s submission, despite the language mismatch, low trust score, and brand ownership.
The product page displayed nothing because the winning contribution was in a language that did not match the marketplace locale. The system did not fallback to the next-best contribution. It simply rendered the attribute as absent.
So to be clear, this contributor was not a data augmentor. It was a hijacker.
The logic behind hijacking through foreign-language contributions is simple: if you provide content in a language the marketplace does not display, the system will not show it to customers, but it will still rank it.
This blocks the legitimate brand owner’s content from appearing without leaving an obvious trace. The brand owner cannot see the foreign-language contribution in Seller Central. They only see blank attributes and assume their submission failed.
The only way to detect this condition was to inspect the catalog backend, contact the exact Amazon team or infer it from the pattern: successful submission, no error, no display, and brand ownership.
With that being said, this is not a bug. It is how the contribution ranking system operates when exploited. The system is designed to prevent low-quality overwrites, but it does not distinguish between a low-quality Amazon contribution and a high-quality seller contribution when the ranking algorithm places the Amazon source higher by default. It also does not automatically discard contributions simply because they are in the wrong language for the marketplace.

In cases like this, the hardest part is recognizing that the problem lives in the contribution ranking layer, not the submission process.
When Amazon accepts your data but does not display it, you can either have our team fix the issue or spend weeks resubmitting the same data that will never win.
Though Process
How we evaluated the system before acting
The first instinct was to resubmit the data. This wouldn’t have worked, the system had already rejected it due to character limit violation.
The second option was to open a case with Seller Support. This would have resulted in a standard response stating that catalog updates take 24 hours to process. Without proper escalation, the support agent would not have visibility into the contribution ranking conflict.
The third option was to assume the data was corrupt or incorrectly formatted. But the data had been accepted without error, and no validation failure was logged. This ruled out a formatting issue.
The question most people ask at this stage is:
“Why did my updates not appear if they were accepted?”
This forces an investigation into what’s currently winning and why. Opening an investigation revealed the winning contribution was in the wrong language, from an internal contributor with a low trust score (when compared with the brand owner).
So this wasn’t data enrichment, since data augmentors add missing information, they don’t replace accurate brand content with unreadable foreign-language text. This is deliberate obstruction.
Initial hypothesis: hijacking through contribution ranking manipulation.
But when we submitted via flat file, validation revealed the real issue: the ingredients exceeded 500 characters. This was a validation problem that the UI failed to communicate.
A normal Seller Central update doesn’t always surface validation errors. A flat file resubmits the complete data and provides explicit validation feedback, allowing us to identify and fix the character limit issue.
